このページはtoggleボタンのサンプルページです
要素の表示・非表示を切り換える、それがtoggleボタンです。
この機能を使って、画像の切替も実現可能です。
なお、説明と画像は一切関係がありません。
この機能を使って、画像の切替も実現可能です。
なお、説明と画像は一切関係がありません。


yaml.erbをyamlに変換するスクリプト
yaml内で変数を使いたかったので、erbと組み合わせて実現した。
個人的な備忘録として書き残しておく。
早速だがyaml.erbをyamlに変換するスクリプトは以下の通り。ファイル名はymlerb2yml.rbとする。
require 'erb' require 'yaml' # VARIABLE DEFINITION var1 = 'bbb' var2 = 'ddd' # FORMAT TRANSLATION yml_erb = ARGF.read() ruby_data_type = ERB.new(yml_erb).result(binding) yml = YAML.load(ruby_data_type) puts yml.to_yaml()
動作確認には以下のyaml.erbを用いる。ファイル名はtest.yml.erbとする。
- aaa - <%= var1 %> - ccc_<%= var2 %>: eee
実行結果は以下の通り。
# ruby ymlerb2yml.rb test.yml.erb --- - aaa - bbb - ccc_ddd: eee
ワンライナーでやると以下の通り。
# ruby -r erb -r yaml -e "var1 = 'bbb'; var2 = 'ddd'; puts YAML.load(ERB.new(File.open('test.yml.erb').read).result(binding)).to_yaml()"
---
- aaa
- bbb
- ccc_ddd: eee
こんな感じでやりたかったことやれたっぽい。
Ruby / Rails ビギナーズ勉強会(第11回)登壇レポート
- [3/16追記] 発表動画をYouTubeに挙げていただいたので、リンクを貼りました。
2月27日(土)にRuby / Rails ビギナーズ勉強会で発表してきた。
タイトルは「Railsチュートリアル完走後の次の一歩」。
発表資料はこちら。
準備や発表を通じて感じたことを簡単にまとめる。
スライド作成
- スライドのデザインを考えるときはまずノンデザイナーズ・デザインブックを参照した。特に配色の考え方が参考になった。
- 文字色のベースを黒じゃなくて灰色すると綺麗というツイートを見て、そのようにした。
- フォントは「Noto Sans」が綺麗と聞いて試してみたが、「Meiryo UI」のほうが好きだったので、そちらを使った。
- 今回の発表資料はそれなりに時間をかけてこだわれたので、今後また発表資料作るときはこれを参考にしようと思う。
- クリップアートや画像を探すのにやたら時間がかかってしまった。会社だと会社でクリップアートを用意してくれていて、それを使えばいいのだけど。
発表
- 練習のとき12分くらいかかっていたので、ちょっと急ぎ目でやったら8分かからず終わってしまった。かなり早口になってしまっていたと思う。反省。
- 発表練習しまくって、できれば資料の内容は暗記しておきたいと思った。スクリーン見るために後ろ向いたり、手元のノートPC見るために顔を落とすのは見栄えが良くないので。
発表内容
- 資料を作る前は、内容簡単すぎて発表する意味ないかと思ったけど、資料を作っていたら、それなりに意味のある資料を作れている気がしてきた。
今作っているアプリをとりあえず作りきって、今年中にもう一回発表したいと思う。
発表動画
Amazon Aurora東京ローンチ記念セミナー参加レポート
11/10(火)、目黒で開催されたAmazon Aurora東京ローンチ記念セミナーに参加してきたので、レポートをまとめておく。なお、数値などは聞き間違いがあるかもしれないので、詳しくは発表者の資料や公式のドキュメントを参照してほしい。
セミナーの感想
セミナーを通してAmazon Auroraはエンタープライズレベルの要件に耐えうるスケーラブルなRDBMSであると、自分なりに咀嚼して理解できたのがよかった。
Auroraの特徴のうち、特に衝撃だったのは次の3点だった。
- MySQLの5倍の性能
- 秒オーダでのフェイルオーバ
- Auroraはマスタは1つなので、マスタ障害時にはフェイルオーバが発生する。リードレプリカがある場合、フェイルオーバ時間は30秒ほど。MariaDB Connectorと組み合わせたら1~2秒になったという事例がある。
- お手軽マイグレーション
セミナー後調べたこととか考えたこと
- Auroraの資料見たところ、なんとAuroraはPostgreSQLと同じ追記型らしい。
これによりバックアップなどの運用性向上、書込性能の向上が実現されているとのこと。 - Auroraは可用性99.99%で設計されていて、SLAは99.95%とのこと。この数字が今後向上したら世の中のシステムはどうなるんだろう。
- NoSQLが出てきたとき、「NoSQLがRDBMSに取って代わることはなくて、適材適所で使われるようになる」という話があったと思う。
これに対してAuroraは、「Oracle, SQL Server並みの性能を、MySQL, PostgreSQL並みのコスト、運用性で」というセミナーでの発言が示すとおり、これから全てのRDBMSの領域を置き換えていく可能性のあるサービスだと思った。 - これからもたくさん事例が出てくると思うので、そのあたりウォッチしていこうと思う。
以降はセミナー中に取った聴講メモなど。
はじめのあいさつ
最初はAWSJ安田さんの挨拶。
Talend、DataSpiderといったデータ連携のツールが既にAuroraに対応。
ウイングアーク1st株式会社は自社製品の中でAuroraを使っているとのこと。
Using Amazon Aurora for Enterprise Workloads
AuroraのGMのDebanjan Sahaさんのお話。
聴講メモ
- Auroraはエンタープライズ利用を想定して設計してある。
- MySQLに完全互換。MySQL向けアプリはそのままAuroraで使える。
- 性能はOracle, SQL Server並、運用のしやすさ、コスト効果はMySQL, PostgreSQLというところを狙っている。
- Master障害時のフェイルオーバ時間は30秒以内。
- MySQLでは数分かかるようなクラッシュリカバリがほぼ即時に実行される。
- 最大50万回/秒の読込、10万回/秒の書込性能。これはMySQLの5倍。
- ストレージ自体がDB用に設計されている。
- これらがフルマネージドサービスになっている。すぐ使えるし、パッチも自動で当たる。
- AWS史上最速で成長しているサービス。
- 国連でも使っている。公開事例になっていなくても、多くの会社がAuroraを使っている。
- 事例1: Expedia
- リアルタイムでのBIと分析が要件。現行はSQL Serverベースのアーキテクチャだったが、高価だった。またスケールしなかった。 そこでCassandraとSolrを組み合わせてインデックスを作成したが、これは大きなメモリー空間が必要で、結局コストが高くなってしまった。
- 事例2: Pacific Gas and Electric Company
- この顧客特有の事情として、停電時にバーストトラフィックが来るので、これを捌かなければならないという事情があった。
- 事例3: ISCS
- 現行ではOracleとSQL Serverを通常業務とDWH用途で使用。これらのコストがIT費用の中で最も大きな支出になっていた。
- Auroraの利用により、70%安価なシステムを実現。
- 事例4: Alfresco
- 事例5: Earth Networks
- 25TB/日で増えるデータの処理をする必要があった。(IoT関連の事業をやっている会社なのかな?)
- 事例6: threat stack
- これもCassandraからの移行事例。
- 高可用性を支える技術
- 3つのAZにまたがり6つの複製を保持。
- Peer-to-pper gossipレプリケーション
- 6つのうち2つを失っても性能は落ちない。6つのうち3つを失っても読み込みは可能。
- 高速なクラッシュリカバリ
- 普通はチェックポイントが5分間隔とかで、ログをシーケンシャルに適用する。時間がかかる。
- Auroraは、Disk readの一環として、オンデマンドでredo logの適用を行う。そのため、リカバリ時にredo logを当てる必要がなく、1秒以内でのリカバリが実現できる。
- AuroraとMariaDB Connectorにより、さらに短時間でのフェイルオーバが可能。
- バックアップについて
- 各DBのスナップショットを定期的かつ並列で取得し、REDOログをAmazon $3へ転送する。
- 適用型スレッドプール
- この辺りはMySQLの実装とかなり違う。(詳細聞き逃した。)
- 非同期グループコミット
- 6つのうち4つのDBでコミットがされた時点で、データの書込みが成功する。
- Advanced monitoring(開発中)
- 顧客からの要望のあった、OS関連メトリクスを取得できるようになる。
- Cloud watchは1分間隔だが、Advanced monitoringは1秒間隔でメトリクスの取得ができる。
- AuroraはMySQLと比べてもコスト効果があることがある。
Q&A
- Q MySQLの場合、データサイズが大きくなるとDDL変更が時間がかかるが、Auroraはそのあたり改善しているのか?
- A いくつかは改善しているが、全てではない。オンラインでのDDL変更については、現在開発中。
- Q モバイルSDKから直接使えるか?
- A 使える。
- Q インスタンスタイプR3しかないが、今後の展開は?
- A 現時点では、T2タイプを今後サポートしたいと考えている。M, CあたりはAuroraのアーキテクチャを活かせないので、考えていない。
- Q メモリに載らない大きなテーブルのalter tableしないほうがいいという話があるが、現在は?
- A おおよそ修正済み。ただ超巨大なテーブルをalter tableするのであれば、大きなインスタンスタイプを利用することをオススメする。
- Q MySQLのMHA(数秒でのインスタンスタイプ変更)のような機能は提供されているか?
- A MHAはサポートしていない。そのような場合の対応方法としては、大きなインスタンスにリードレプリカを作っておいて、そこにフェイルオーバするのを推奨している。
Nice to meet you, Aurora! ~RDS for MySQLからAuroraへの移行~
株式会社Grani @guitarrapc_techさんの発表。発表前に資料公開されていて、ありがたかった。
資料
聴講メモ
- 性能改善について
- NewRelicでざっくり見る。個々のクエリはBigQueryで見る。
- 参照は変わらなかった。
- 更新が5倍速くなった。5倍というアナウンスどおりの結果が出た。
- インサートも速くなった。
- 削除は若干遅くなった。
- 移行について
- MySQLだと高負荷時にダウンしてしまうことがあった。Auroraはスローダウンすることはあっても、動き続ける。
- 年間2200万円のコスト削減効果。
ドワンゴがAurora使ってみた(仮)
株式会社ドワンゴ 細川さんの発表。
聴講メモ
- これまでのはなし
- Aurora適用プロジェクト
- 検証結果・パフォーマンスなど
Amazon Aurora 評価・検証結果発表
アイレット株式会社 cloudpack 新谷さんの発表。
実データを用いたAurora検証結果の報告。
Amazon Auroraはこう使おう!
~基幹業務をフルクラウド化するポイント~
ウルシステムズ株式会社 漆原さんのお話。
聴講メモ
- これまでRDBMSとNoSQLという極端な2択しかなかった。基幹業務系やっていて、ずっとクラウド型のRDBMSが欲しいと思っていた。
- オンプレをそのままクラウドに持っていくと、インフラコストの削減にはなるけど、それしかない。その先へ。
- モノリシックな業務APが、今、すべてを邪魔している。このままAuroraにいっても、それからどうしようもなくなる。
モノリシックなものをマイクロサービスへ。APIで綺麗に切りなおして、そこからしかアクセスさせないようにする。
オーバヘッドはあるが、その代わりスケーラビリティが得られる。こうすることで、Auroraの特性をフル活用できる。
New Cloud Design Pattern using Amazon Aurora
クラスメソッド株式会社 大栗さんのお話。
聴講メモ
- Develpers.IO移行事例
- Developers.IOをAuroraに移行した。性能向上した。
- もともとdb.m3.mediumだったので、db.r3.largeになって、コストは1.5倍になった。
- 某SNS移行事例
- これ以上DBのスレーブ増やせない状態。移行検討中。
- 高速なフェイルオーバ
- OSS DBと比較して低価格の場合もある。インスタンス台数が削減できる場合があるので。
Amazon Aurora+ScaleArcによる Amazon Aurora のデータベース分散処理技術の最大活用
株式会社システムサポート 山口さんのお話。タイトル違うかも。
ScaleArcという製品の紹介。
エンタープライズシステムにおける Amazon RDS for Aurora 活用ノウハウ
株式会社野村総合研究所 西岡さんのお話。
聴講メモ
- Auroraは可用性99.99%で設計されていて、SLAは99.95%。
- Auroraは現状参照しかスケールしない。
その他
- Amazon Aurora TシャツとAurora利用クーポンの抽選があったけど、外れた。Tシャツ欲しかったな。残念。
- アマゾンのセミナールーム、発表者の立つところに神棚があって、意外と日本ぽいんだなーと思った。
 けどよく見たらドアだった。しかもセミナールーム中にいっぱいあった。どういうことなの。
けどよく見たらドアだった。しかもセミナールーム中にいっぱいあった。どういうことなの。

YAPC::Asia2015参加レポート(Day2)
8月21日(金), 22日(土)に、YAPC::Asiaに参加してきた。
YAPC::Asiaは今年で最後ということで、会場はなんと東京ビッグサイトだった。
参加セッション一覧
私が参加した8/22のセッションは次の通り。
- 8/22
- ISUCONの勝ち方 by Masahiro Nagano
- NASA主催の世界最大級ハッカソンSpaceAppsを運営した話 by Tsubasa YUMURA
- Docker3兄弟について by アルパカ大明神
- Adventures in Refactoring by Ben Lavender
- Posture for Engineers by Marylou Lenhart
- Run containerized workloads with Lattice by Etourneau Gwenn
- Profiling & Optimizing in Go by Brad Fitzpatrick
セッションの感想&内容
参加したセッションの感想や内容を書く。
なお「内容」は、理解し切れていない部分や誤解もあるはずなので、参考程度に見て欲しい。また誤りを指摘できる人は指摘して欲しい。
ISUCONの勝ち方 by Masahiro Nagano
感想
- ISUCONに参加したことはなく、過去問なども見たことはなかったが、毎年Twitterで盛り上がりが伝わってくるISUCONというものがどんなものか知りたくてこのセッションを聞いた。
- プロファイリングツールについての話が興味深かった。言語別のプロファイリングツールもあるが、それよりもstrace, tcpdump, lsof, dstatなどのコマンドのほうが役立つということだった。このあたりのコマンドは使ったことはあるが、使いこなせているかというとそうでもないので、しっかり勉強しておこうと思った。
- コンテキストスイッチの説明、Apacheとnginxのプロセスモデルの違いの説明がわかりやすかった。
- ISUCONの対策資料は結構ネット上にあるようなので、目を通しておこうと思った。
NASA主催の世界最大級ハッカソンSpaceAppsを運営した話
資料
感想
- この発表を聞くまでSpaceAppsを知らなかったが、すごく楽しそうなハッカソンだと思った。こういうハッカソンに参加できるくらいの技術力を身に付けたいと思った。
Docker3兄弟について by アルパカ大明神
資料
感想
- Docker Machineは発表された当初に触ったことがあったが、Compose, Swarmは触ったことがなかったので、使用感知りたくて参加した。
- スピーカーの方は触っただけではなく、開発環境で実際に使っていて、特に問題なく使えているということで、それだけでも貴重な情報を聞けたと思った。
- 副題に~そして4兄弟へ~とあり、Docker4兄弟というのはDocker Networkのことかと思ったけど、Docker Toolkitのことだった。
Adventures in Refactoring
感想
- 業務でリファクタリングをしたことはなくて、ちょっと前までリファクタリングなんて全然興味なかったけど、Rebuildでリファクタリングの話を聞いてから、リファクタリングにはリファクタリングの美学があるんだと知り、そのあたりの話が聞きたくて参加した。発表内容は期待通りリファクタリングの美学についての話だった。
内容
- シングルクウォーテーションとダブルクウォーテーションの両方が使われている箇所をどちらかに揃えて一貫性をとるようなリファクタリングは、やってもいいが、リファクタリングの目的としては正しくない。
- リファクタリングは、リファクタリングの前後で改善点を評価できなければならない。行が減ったのであれば、それはその分バグの潜在するリスクを減らしたと評価できる。リファクタリングの結果行数が増えるのはいけない。
- リファクタリング中にバグを見つけても、そのバグを修正すべきではない。バグが悪いのか、リファクタリングが悪いのか分からなくなってしまうため。
- Goのgo fmtは素晴らしい。
- Javaは言語レベルでDeprecatedをサポートしている点が素晴らしい。
Posture for Engineers
感想
- スピーカーは、エンジニアやりつつヨガの講師もやっているという女性。Postureは姿勢という意味。
- 技術的な内容ではないが、ヨガやっていたこともあって興味があったので、気軽な気持ちで参加した。
- トーク中にみんなで席から立って腰や肩にいい立ち方をして、思い出に残った。
内容
- 「椅子に座る」という動作自体、人間の歴史からすると最近の出来事なので、長時間使っていたら負担も大きい。
- 長時間座っていると股関節が固まってくるので、意識して1時間に1回立つようにするのが大事。
- バランスボールに座って仕事をしたり、スタンディングとシッティングを適度に織り交ぜながら仕事をするのがオススメ。
Run containerized workloads with Lattice
感想
- Lattice含めCloudffoundryあたりのこと全く知らなかったので、基本的な内容ざっと知れてよかった。
内容
メモそのまま。。。
- LatticeはCloudfoundryのサブセット。スケジューラもあり、diegoという。
- cloudfoundryはインストールしにくい。不要なのも一緒にインストールされる。だるい。
それで機能は少ないが、簡単にインストールできるlatticeが作られた。 - Latticeはパーシステントデータはサポートしていない。あくまで開発用。
- Dockerにはロードバランシングやオートヒーリングがない。
- K8sもあるが、最高ではない。単なるスケジューラに過ぎない。
Profiling & Optimizing in Go
資料
Go Debugging, Profiling, and Optimization
感想
- Goそんなに書いたことがなくてついていけない部分も多々あったけど、Goにはpprofという強力なプロファイリングツールが備わっていて、webというコマンドでプロファイリング結果を図示することまでできることがわかった。
YAPC全体の感想
- YAPCには昨年、今年と参加したが、本当に楽しかった。
- YAPCはPerlだけにとどまらない技術の祭典という感じで、本当に素晴らしいイベントだったと思う。今年で最後なのが惜しまれる。
- 普段Twitterでフォローしているエンジニアの方のトークを聞くのは本当にモチベーション上がる。
- LTではbotの話題が多かった。この辺りはこれからまだまだ面白いことやる人が出てきそうな予感がして、期待大。
- ベストトークの2位、3位はHTTP2関連だったということで、HTTP2勉強しなきゃな、と思った。
- Consulの話も随所に出てきていたっぽい。
- あらかじめ準備されていたトークだけでなく、会場で話をしたエンジニアの方のレベルの高いディスカッションの内容も伝わってきたりして、本当有難い感じだ。→OSS開発の活発さの維持と良いソフトウェア設計の間には緊張関係があるのだろうか?
- ノベルティのサイリウム良かった。子供めっちゃ喜んでた。
YAPC::Asia2015参加レポート(Day1)
8月21日(金), 22日(土)に、YAPC::Asiaに参加してきた。
YAPC::Asiaは今年で最後ということで、会場はなんと東京ビッグサイトだった。
参加セッション一覧
私が参加した8/21のセッションは次の通り。
- 8/21
- メリークリスマス! by Larry Wall
- Managing Containers at Scale with CoreOS and Kubernetes by Kelsey Hightower
- Consulと自作OSSを活用した100台規模のWebサービス運用 by fujiwara
- Perlで学ぼう!文系プログラマのための、知識ゼロからのデータ構造と計算量 by Shinpei Maruyama
- Electron: Building desktop apps with web technologies by Ben Ogle
- esa.io - 趣味から育てたWebサービスで生きていく by Atsuo Fukaya
セッションの感想&内容
参加したセッションの感想や内容を書く。
なお「内容」は、理解し切れていない部分や誤解もあるはずなので、参考程度に見て欲しい。また誤りを指摘できる人は指摘して欲しい。
メリークリスマス! by Larry Wall
感想
- スピーカーはPerlを作った方。英語めっちゃ聞きやすかった。
- Perl5, Perl6はホビット, Load of the Ringと似てるみたいな話をしていた。LotRネタわかったので、ニヤニヤしながら聞いてた。
- Perl6を今年のクリスマスに出せるように頑張ると言っていた。
Managing Containers at Scale with CoreOS and Kubernetes by Kelsey Hightower
感想
- デモを交えたKubernetesの解説。
- 8/19のDocker Meetup #5で同じプレゼンを聞いてはいたんだけど、そのときは同時通訳がなくてほぼ理解できなかったので、もう一回聞いた。今回は同時通訳のおかげで、概要は何となく理解できた。
- デモが良かった。コンテナ時代のアプリ管理はこうなっていくんですよ、と概念的に説明されていたところを、実際にデモしてくれたという印象。
- Kubernetesのダッシュボードがかっこよかった。
内容
- 「Ansibleなどの構成管理ツールは、"マシンの管理"というところに重きを置いているため、物理サーバ、VMの管理には向いていても、アプリの管理には向いていない。それではアプリがスケールしないので、アプリの管理はスケジューラでやる。」という導入の後に、スケジューラとしてKubernetesが紹介された。
- 続いてKubernetesの構成要素として以下が紹介された。
- node: CPU, メモリなどのリソース
- pod: コンテナを束ねる単位。1つのpodの中ではnamespaceを共有する。
- scheduler
- replication controller: podの数を1つから3つに増やすときに使う。自己回復機能がある。
- service
- その後のデモでは、pod内のコンテナの増減やバージョンアップの様子がデモされた。canaryパターンというものが紹介されていたが、何なのかよくわからず。
- 質疑応答
- Q 様子がおかしなコンテナのトラシューはどうするのか?
- A トラシュー用のpodを作ってそこでトラシューするのが良い。
- Q Immutableの文脈では、開発環境で試験したコンテナをそのまま商用環境に持っていくという話があるが、Kubernetesもそうするべきか?
- Q パーシステントデータの扱いは?
- A (Kubernetesの)Schedulerではパーシステントデータを持つPostgreSQLのようなDBは扱えない。etcdを使う。
- Q 様子がおかしなコンテナのトラシューはどうするのか?
Consulと自作OSSを活用した100台規模のWebサービス運用
資料
感想
- Consulは気になりつつ触ったことなかったので、実運用で得たノウハウを聞けて大変参考になった。とくにConsul導入の目的が聞けてよかった。Consulの機能は何となく知っていたが、使いどころがわかっていなかったので。
内容
- Consul導入の目的
- Serverは3台以上推奨で、1台がleaderとして選出される。(Raftアルゴリズム)
- 使いやすいKVS機能がある。デフォルトでは、問い合わせに応答できるのはleaderノードだけ。なので負荷はleaderノードに集中する。stale modeにすると他のノードでも応答できるようになる。
- メモリフットプリントは20MBくらい。省リソース。ディスクIOhは少ないところに入れるべき。
- leaderノードがクラスタはずれた際の次のleaderノードの選出は2~3秒で終わる。その間DNS引けなくなる。それが挙動できないならstale modeを使う。
- クラスタは一度動かしたら基本は止められない。
- オペミスでクラスタが崩壊するとKVが消えるので要注意。定期的にバックアップを取っておく。
Perlで学ぼう!文系プログラマのための、知識ゼロからのデータ構造と計算量
資料
感想
- 期待していた内容を聞けた。2日間で一番満足度が高いセッションだった。
- データ構造、計算量、DBのアクセス方法のそれぞれは知っていたが、自分の中でそれらが全然繋がってなかった。このセッションがその部分を繋げてくれた。
- 何かの書籍の内容をそのまま講演にしたのではないかというくらい、体系だっていてわかりやすかった。
- 2日目の「ISUCONの勝ち方」で早速B+木の話が出てきて、この発表聞いておいて良かったって思った。
- オススメ参考書籍はないということだったが、自分が知る限り、データ構造についてはこの本が分かりやすかった。C言語ポインタ完全制覇
内容
- スピーカーはprocess-book書いた方。
内容
当日のメモそのまま貼り付けただけ。。。
事前知識
- shortは2byte。だけどメモリの番地はintだから、short*は4byte使う。
- じゃあshortって何なん?→メモリの番地読みいったとき、先頭の番地は分かっても、
そこから何byte読めばいいかわからん。ここでshortというデータ型が必要。
データ構造
- 値そのものと指し示す値
No.1 配列
- Cの配列って面白くて、必ず連続したメモリ領域に配列を確保する。
- 問題もある。追加で要素が欲しいとき、次に配列領域伸ばせるかって言うと、分からない。
もう使われているかもしれない。
No.2 単方向連結リスト
- 配列は連続したメモリ空間でないといけなかったが、連結リストは飛び飛びでOK。
- 配列は計算して目的の変数に一発アクセスできたけど、連結リストだと
じゅんぐりじゅんぐり計算しないと一発アクセスはできない。
計算量の話
- オーダー法。n回の計算も2n+1回の計算も、オーダー法的にはO(n)。
- 配列はO(1)?かな。
- 連結リストはO(n)。悪くないけどO(log n)だと嬉しいよね。
2分木
- 2分木で探索するとき、全部見なくていい。O(log n)で済む。
- 意味ないとき→最初が1で次に1→2→3→4となっている場合。
いやこれって連結リストじゃん、ていう。
B木
- 勝手にバランスしてくれる木。
- 満員になったら真ん中のやつを上にしていく。
- 木の枝を降りていく計算は基本O(log n)
- 問題: シーケンシャルアクセスやりにくい。
B+木
- DBのインデックスとかに使われているやつ。
- B木は値をmoveしているところ、B+木はcopyする。
するとリーフの部分はシーケンシャルに並んでいる。
Electron: Building desktop apps with web technologies by Ben Ogle
感想
- このあたりHPが底をついてしまって、発表が頭に入ってこなかった。
- Electronという名前と、AtomがElectronの上に構築されているということだけわかった。
esa.io - 趣味から育てたWebサービスで生きていく
資料
感想
- esa.ioというサービスはこの発表を聞くまで知らなかった。
- 端的に観想を言うなら、「カジュアルだな。。。」と。この一言に尽きる。
- 情報共有ツールとしてQiita:Teamを使っていたが、有料になったので、同じようなものを自分で作った。それでいけそうな手ごたえがあったので、会社作ってそちらに専念することにしたと。
- いくつもサービスを作って経験を積み、いけそうなサービスで勝負する、というのは素晴らしいと思った。
- スピーカーがサービス開発において取り組んでいることは、既にWebなどで「こんな風に開発するといい」といわれていることが多くて、斬新なことをやっているという印象は持たなかった。これは、今「こんな風に開発するといい」とされていることをきっちりやれば、食べていけるようなWebサービスを作ることができる、ということを証明してくれているので、他の開発者にとっては希望になると思った。
- 情報共有ツールの現状のシェアでいえばQiitaのほうがリードしていそうなので、今後の展開に注目していこうと思う。
JTF2015参加レポート
まえおき
今年もJTFに参加してきた。
去年はJuly Tech Festaといいつつ6月だった気がする。
個人的には、開催時期は6月のほうがうれしい。
7月後半は子供たちが夏休みということもあり、6月に比べて世間で他にもいろいろ魅力的なイベントがやっているので。
まぁまた来年もやるなら7月でも行きますが。
簡単にレポートを書く。
ベンチャーCTO、AWSエバンジェリストを経て考える、クラウド時代に向き合うエンジニア像のこれから(@horiuchi)
資料
感想
- 「AWSの堀内さん」しか知らなかったので、堀内さんのこれまでの経験を踏まえて、これからのエンジニア像を語ってくれた本セッションは面白かった。
- 堀内さんがAWSのエバンジェリトだった頃、AWSの新サービスが登場する度にそのサービスの概要やメリットを分かり易くユーザ伝えている堀内さんを見て、何故こんなに幅広い分野のサービスを理解できるのだろう、と不思議に思っていた。
この発表を聞いて、それを可能にしていたのは、ベンチャーCTO時代に様々な技術に触れた経験が大きかったんだろうな、と思った。 - なので、最後にスタートアップCTOがお薦め、という話が出てきた時、それまでの話の流れからガラっと変わった印象を持ちつつ、妙に納得した。
マイクロサービスで、一歩先行くImmutable Infraを目指そう(@sho7650)
資料
ざっくり要約
稼動したシステムには変更を行わない"Immutable Infrastructure"という考え方が出てきた。
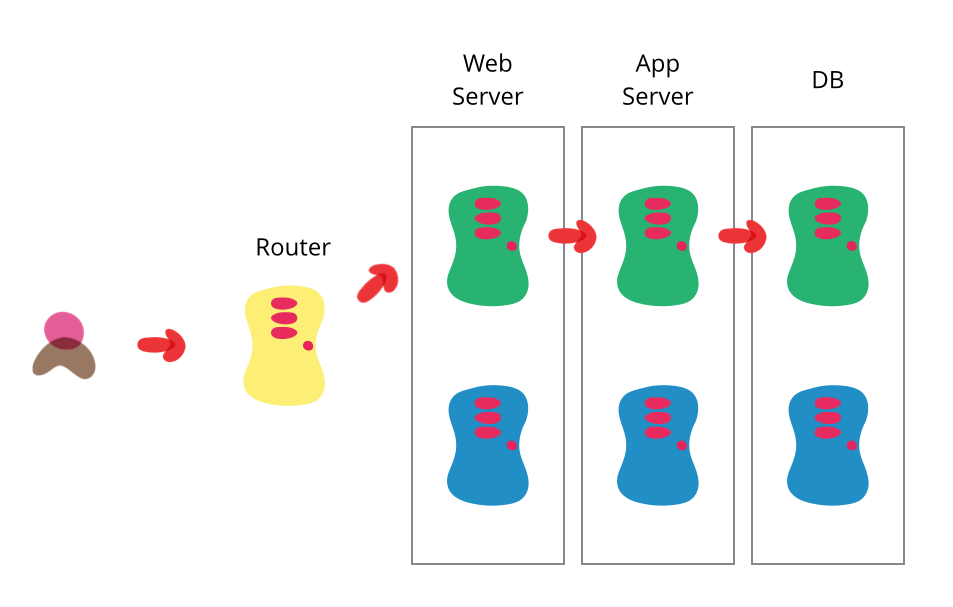 mmutable Infrastructureを実現するときは、ステートレスなサーバ(Web, App)とステートフルなサーバ(DB)でやり方を変えよう、というのが今の流れ。
mmutable Infrastructureを実現するときは、ステートレスなサーバ(Web, App)とステートフルなサーバ(DB)でやり方を変えよう、というのが今の流れ。
上記のようなシンプルな図を眺めている分にはそれで良さそうに思えるが、実際にImmutable Infrastructure実現しようとしたら、話はそう単純ではない。
エンプラなシステムなどは接続先がたくさんある。あるサーバ切り替えて周りのサーバが落ちる可能性がある。これは課題。
この課題の解決策としてマイクロサービスが出てきた。
マイクロサービスのポイント
コンポーネント化する。
コンポーネント化とは、インタフェイスを明確にすること。ロジックに変更があってはいけない。
- メモリをコンポーネントと考えると、速くなった、容量が大きくなったはOK。機能が削減されて、今まで通ってたロジックが通らなくなったはNG。
上図ではブルーとグリーンでインタフェイスが変わってなければ、どんな複雑はシステムでも、ブルーグリーンデプロイメントできる。
作ったプログラムはプロジェクトとして扱うのではなく、プロダクトとして扱える。
- プロジェクトとして扱うと、始まりと終わりができる。そうではなく、プロダクトとして捉え、開発者が最初から最後までやる。
- 同期はREST, 非同期はMQなどシンプルな構造にする。
最近のマイクロサービスの文脈では、「どうやって?」という部分の話はあまり出てきていない。
そこは、これからみんなの知見が集まっていかないと話ができない部分。
=> SOAの知見が役に立つのでは?
SOA
- マイクロサービスでcomponentといっているものを、SOAだとサービスと言っている。サービスは一番小さな単位。
- サービスの規約は何でもいいと言っている。REST、MQなど手段具体的な実装方法については言及していない。
- だから、SOAはマイクロサービスに比べると、自由度が高い。
- プログラムの考えで言うと、構造体→オブジェクト指向→SOAという流れ。
- Service Repository。サービスを登録しておくところ。サービスのHUBみたいな。
マイクロサービス vs SOA
SOA ロードマップ
- 基礎段階: 保守性の向上
- ネットワーク化段階: カプセル化。中継層に担わせる。中継層・・・技術的に難しいことを担わせる。
プロセス制御段階: 俊敏性の向上。
- SOAのプロセス制御は、普通のセッションより長くセッションを保とうとする。普通ログアウトしたらセッションは切るが、SOAだとログアウトした後も保とうとする。
まとめ
- 新しいものと古いものを組み合わせて使う。
- 車輪の再開発はしない。
- Re-usable not Re-cycle
- もともと再利用可能しておいてそれを使うのと、あるから使うというのは全然違う。後者は辛くなる。
感想
去年会社の勉強会でマイクロサービスって考え方が流行りつつあるらしい、という話をしたら、「それSOAと何が違うの?」と言われて、SOAを知らなかった自分は「???」となった。
RebuildでもマイクロサービスとSOAについて言及してた気がするけど、「SOAはエンプラ臭がする」とかそんな程度の話だった気がする。
そんな感じでマイクロサービスとSOAについてはかなりもやっとした理解しかなかったのだけど、この発表を聞いて、マイクロサービスとSOAの違い、何故マイクロサービスの文脈でSOAを出す必要があるのか、といったあたりを理解することができた。参加してよかった。
MONITORING DOCKER(@jhotta)
資料
なし
ざっくり概要
- datadogで働いている。
- datadogのblogで、監視についての連載を始めた。Monitoring 101: Collecting the right data
- monitoringをDIYしていると、機能追加なんてできない。
- monitoringツールを作ることが、競合との差別化に繋がるのか?というところは考えて欲しい。
- Docker監視で「コレだ!」というのはまだない。
- WHY DOCKER USERS MONITOR
- ステータスみたい
- Docker Engineが壊れているの?特定のコンテナ?それとも周辺ツール?というのが知りたい。
- タグや正規表現によってグループ化できる監視ツールでないと、コンテナの監視は辛い。
- dockerのメトリクス取れる場所(後者2つは正しくない。)
- cgroups
- docker api
- in-container agent direct monitoring
- kernel hacking
- NewReric - eventとmetricsを紐付ける機能が弱い。
- SYSDIG・・・カーネルハッキングしている。
- SIGNALFX・・・今後注目。メトリクスの関連性の取り方とかいい。後発で、勉強してきたイメージ。 メトリクスの測り方は他と違う。
- LIBRATO・・・fluentd
- PROMETHEUS
感想
- コンテナの監視を設計する日が来たらとりあえずdatadogのblogを読んでみようと思った。
最前線で戦う若手インフラエンジニアたちが語る「技術トレンド」と「数年後の未来」(@y_uuk1, @catatsuy, @hfm, @deeeet, @rrreeeyyy)
資料
概要
- ブロッコリーのブログによくまとまっている。
感想
- プロビジョニングツールの話のところで、サーバ設定の"設計の難しさ"とプロビジョニングツール自身の扱いの難しさが混同されることが多いから、そこは話解き分けたほうがいいという話があって、それは確かに気をつけたほうがいいと思った。
- プロビジョニングツールやコンテナなど技術的な話も参考になったが、それよりもチームとして成果を出すためにどんな取り組みをしているかという話が参考になった。特に@hfmさんの研修の話やチームメンバのアウトプットが共有される仕組みづくりの話など。
運用に自動化を求めるのは間違っているだろうか(@zembutsu)
資料
概要
資料を読めばOK。
感想
発表中に出てきた次の2つの考え方がすごくしっくりきた。
- 働いたら負けでござる。刺身タンポポ業や写経文化の中で働いたら負けでござる。
- DockerやHashiCorpのプロダクトが流行っているが、一つのツールが全ての課題を解決できる銀の弾丸になるはずはない。
なのでそれらを手札と捉えて、使えるツールを増やしていき、最強のカードデッキを作るようなイメージを持つ。
おわりに
- 今年もいろいろな話が聞けて楽しかった。来年の参加したい。
- 電源が欲しい、電源が欲しい、電源が欲しい。
- 休憩時間にやっているスポンサーのハイアリングセッションが面白かった。